Live comments in, trending entities out.
Reddit comments flow through Kafka into Spark Structured Streaming, which extracts named entities with NLTK and counts them. Logstash then indexes the snapshots into Elasticsearch, and Kibana sits on top for the dashboards. The whole stack is containerized with Docker Compose, so one command brings the broker, the stream job, and the search layer up together.
Architecture
The flow is a straight line. Live comments enter Kafka, Spark reads and transforms the stream into entity counts, Logstash ships those snapshots into Elasticsearch, and Kibana renders them.

The original one hour run
Before the on demand version, the pipeline ran continuously for an hour against live Reddit. These Kibana snapshots at fifteen, thirty, forty five, and sixty minutes show the entity counts climbing as more comments streamed in.
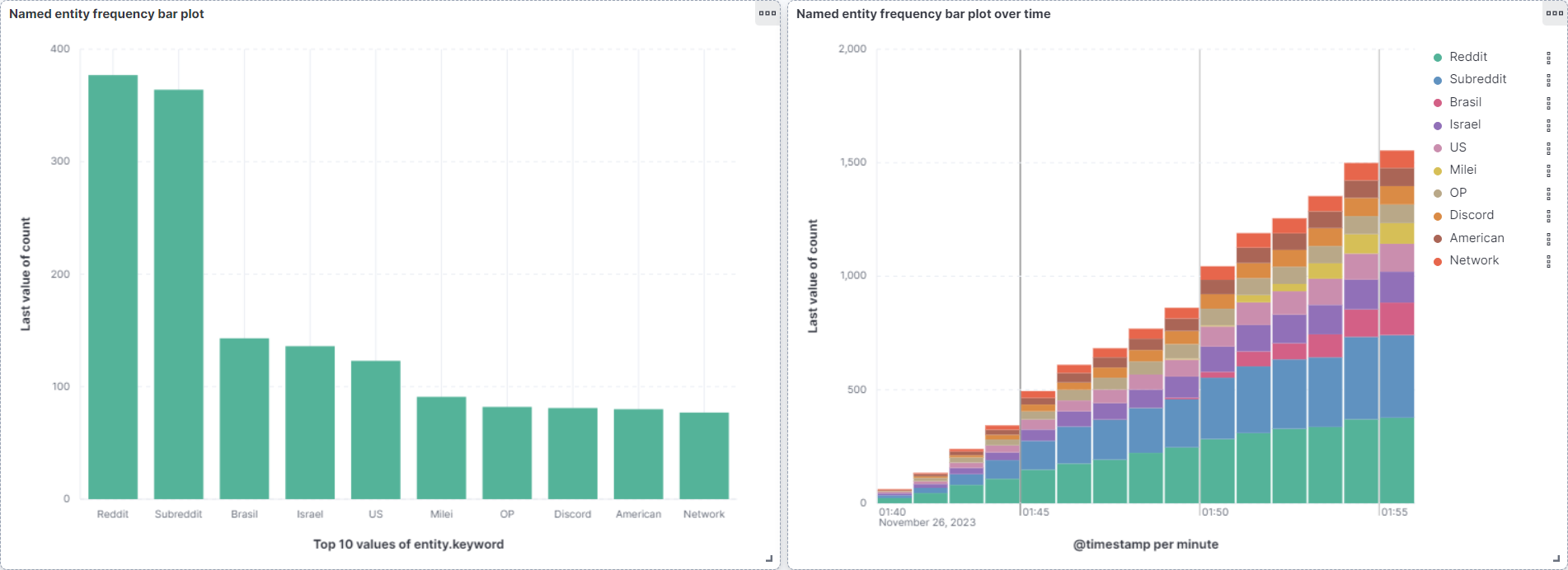
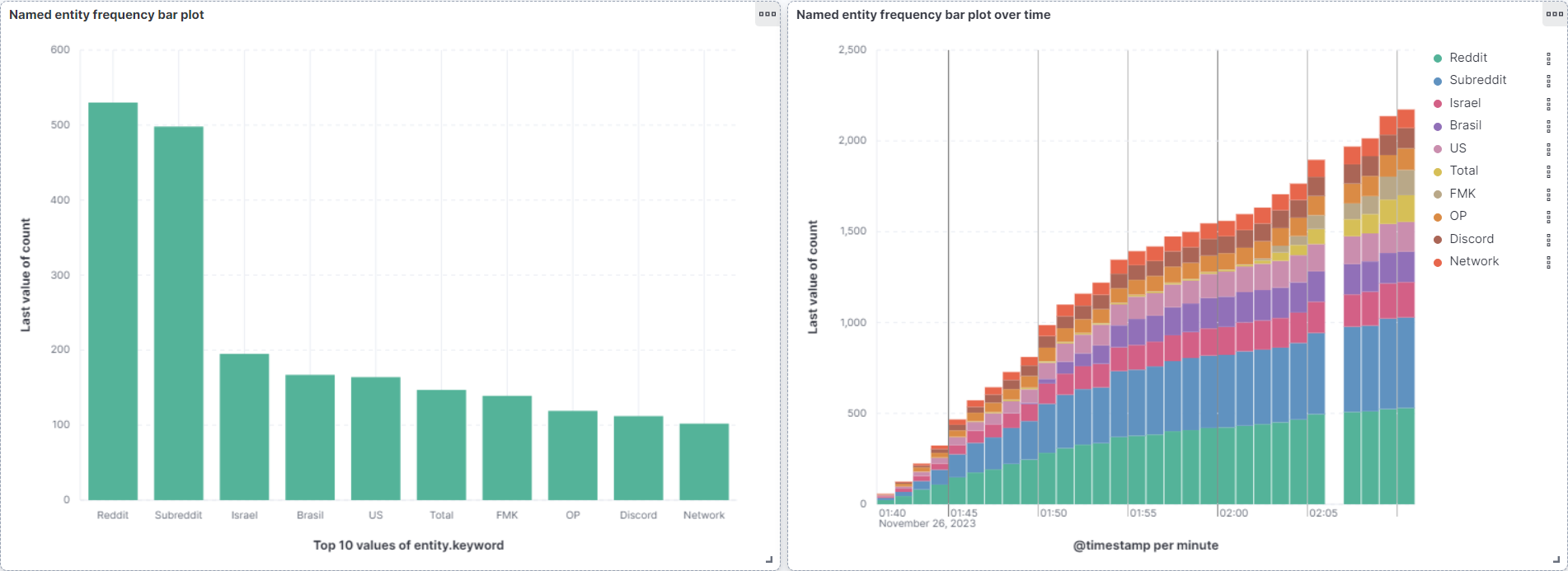
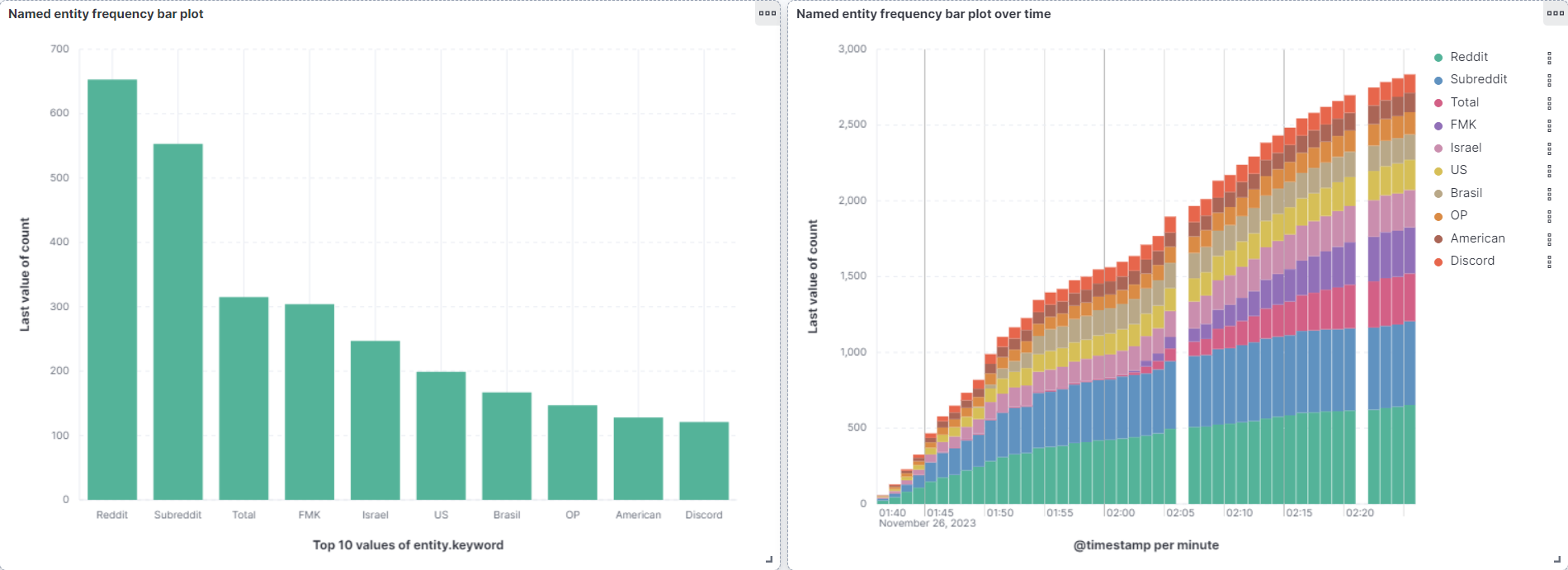
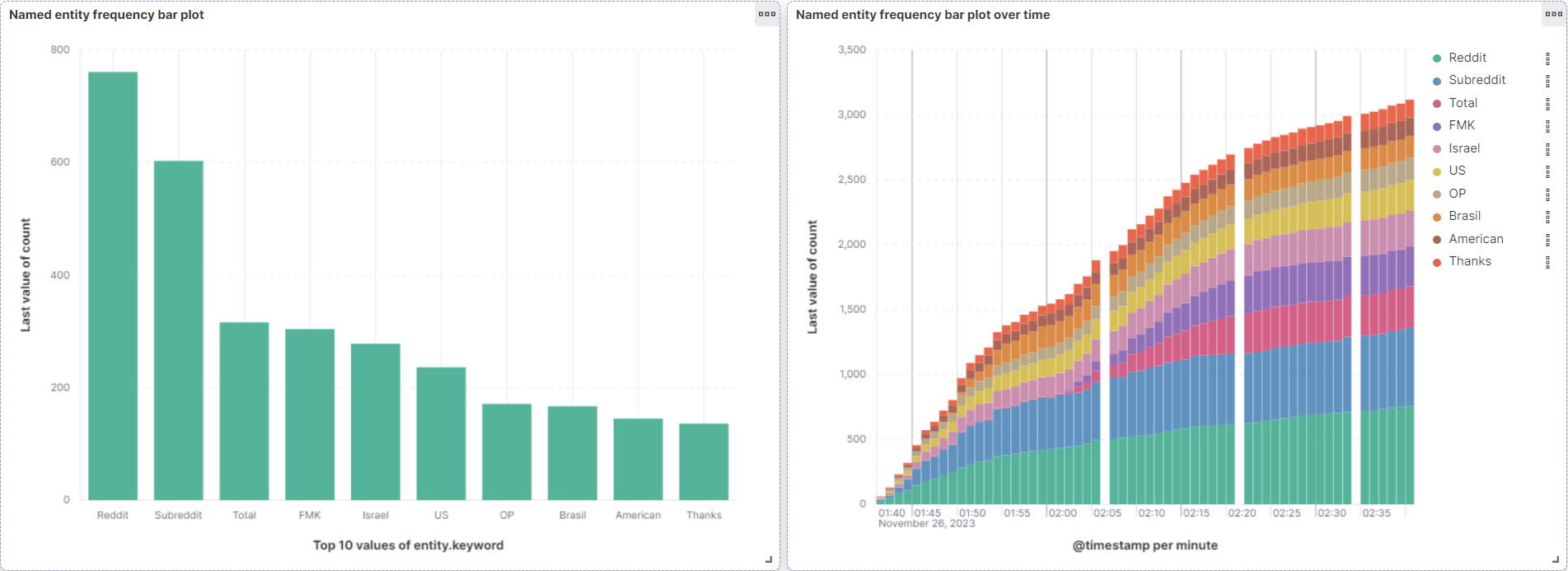
Run it yourself
Clicking run boots the entire stack on a fresh GitHub Actions runner. It streams live comments for about a minute, extracts and counts the entities, publishes the snapshot back to this page, and then everything shuts down. Nothing stays running between visits, so the results below always come from the most recent run someone triggered.
a click boots the real stack on github, streams for about a minute, then shuts it all down.
loading the latest run.
The stack
| Piece | What it does |
|---|---|
| Kafka | the message broker that buffers the incoming comment stream |
| Spark Structured Streaming | reads the stream, extracts named entities with nltk, and counts them |
| Logstash | ships the entity snapshots into elasticsearch |
| Elasticsearch | stores and aggregates the entity counts |
| Kibana | the dashboard that visualizes the trending entities |
| Docker Compose | brings the whole stack up with a single command |
| praw | the reddit api client that pulls the live comments |